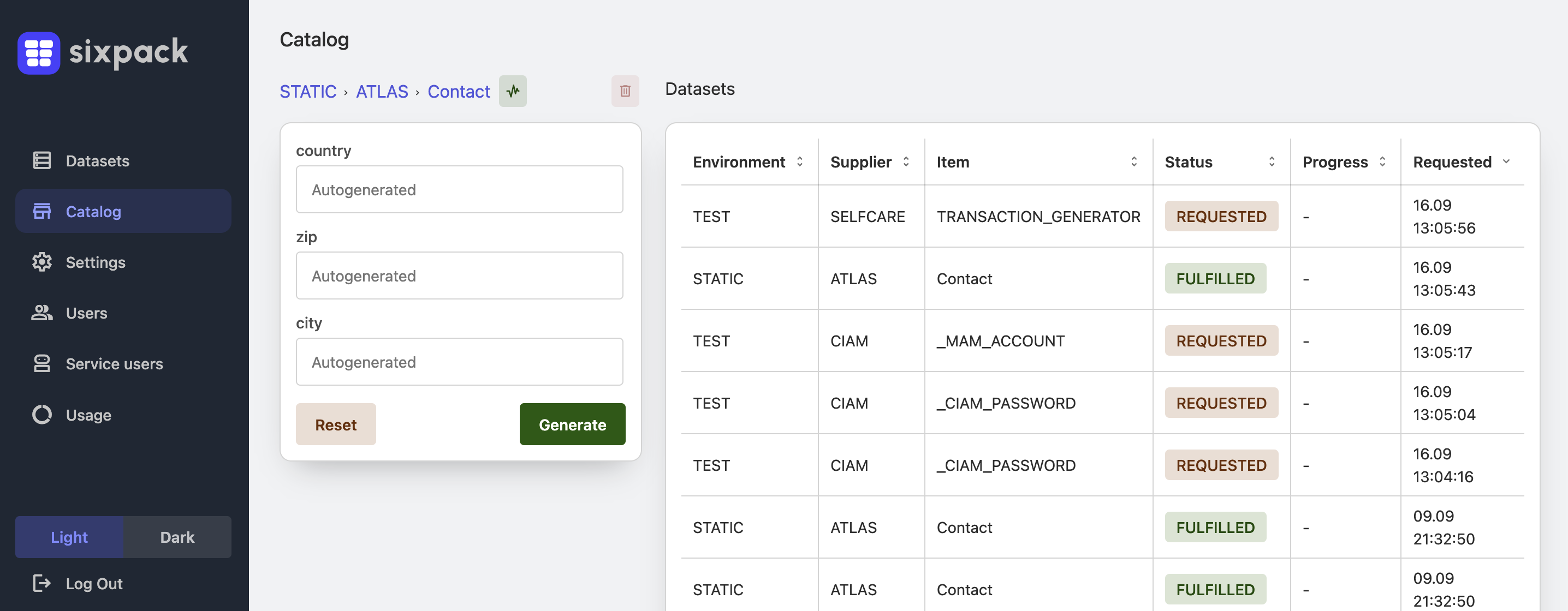



Failure mode
The pipeline is green until test data becomes the bottleneck
Build and deploy may complete quickly, but integrated-environment validation still waits because the required customer, order, or account state must exist consistently across the whole landscape.